
Intro
Sometimes we need to exceed Dataform limits. One case is when you want to query a table and use the result in JavaScript to build other Dataform models.
There could be multiple reasons why you need this. For example, you have an external system or model and you should build your pipelines and tables based on the provided data. Or for example, in Google’s Marketing Solution Compass Project, one of the steps is dynamically generating feature columns based on previous calculations and feature validations. Or if you too pragmatic just treat this blog post as example of Dataform Notebooks usage.
Anyway, unfortunately, it’s not possible by default and we have to use some workarounds. If you want the solution, scroll to the example and skip my bla-bla part about Dataform and my personal preferences.
Dataform execution
But before going directly to the solution section, I want to quickly remind you that Dataform executes workflows in two steps:
- Dataform compiles the code (AKA converts JavaScript (SQLX) to SQL)
- Execute SQL code
I think this is the main reason why we can’t use the result of execution inside the JavaScript helpers. JavaScript exists before step one, and data exists after step two.
But it’s important to remember this two-step approach or it could lead to unexpected surprises. For example, something like this is usually a bad idea:
select '${new Date().toLocaleTimeString()}' as insertDateBecause it’s not the execution time, it’s Dataform compilation time (step 1). So if you compile this model once (if you change something in the Dataform UI, it recompiles the code automatically) and execute it multiple times, you will always get the same value.
Note: Here’s the official documentation with more details about workflow execution.
Possible solutions
EXECUTE IMMEDIATE
Ok, let’s get back to our goal - building models based on data from another table.
The first possible solution - we could forget about JavaScript and try to use EXECUTE IMMEDIATE. I personally hate this. I don’t know why, but for me it’s so scary - creating SQL from SQL and executing it. It smells like the 90’s.
But I think sometimes it’s possible. For example, Simon worked a lot with BigQuery labeling solutions and we discussed EXECUTE IMMEDIATE to process labels. It could be something like this:
| |
Ugly and scary, and of course Simon told me he will never use it. He prefers elegant solutions.
Export to Cloud Bucket
Another possible approach is to export the result to a Cloud Bucket using something like this:
| |
Next, we could create a bucket notification to send Pub/Sub events on file upload. And use this event to trigger a Cloud Function to save the result as a JSON file in the Dataform repository.
I like this approach more than EXECUTE IMMEDIATE. It’s like two steps - one to refresh configuration and the second to run execution based on an updated config file with a little bit of GCP magic in between.
Dataform Notebooks plus Dataform Packages
But Krisz suggested an even better way — why not use BigQuery Notebooks for all Python code to update JSON config? Notebooks are supported natively by Dataform, so we could keep all logic and code inside the same Dataform repository and also reduce GCP magic.
I really like the idea and packed all Python code into two Dataform packages:
- dataform-table-to-json — to export data from BigQuery and save (or update) as a JSON config file inside the Dataform repository.
- dataform-execute-tags — to recompile the repository and run the next pipelines.
Here’s the repository with the full example: dataform-table-to-json-sample
But before using packages, you need to add all dependencies for using Notebooks in Dataform:
- Create a Bucket to save notebook execution results.
- Add the path to this bucket and set
defaultNotebookRuntimeOptions.outputBucketin yourworkflow_settings.yamlfile:
defaultNotebookRuntimeOptions:
outputBucket: "gs://your-output-bucket"
- Enable Vertex API
- Create service account with all needed permissions and use it as a Default Dataform Service Account
To install this package in your Dataform repository, add it to your package.json file (create one in the root folder if you don’t have it):
{
"dependencies": {
"@dataform/core": "3.0.27",
"dataform-table-to-json": "https://github.com/superformlabs/dataform-table-to-json/archive/refs/tags/v0.0.6.tar.gz",
"dataform-execute-tags": "https://github.com/superformlabs/dataform-execute-tags/archive/refs/tags/v0.0.2.tar.gz"
}
}
Notes: You have to delete dataformCoreVersion from workflow_settings.yaml. And @dataform/core should be higher or equal than 3.0.27
And after that, click the Install Packages button.
Ok, after all these steps, let’s dive into the repository with the sample code. The idea is to illustrate a possible use case: create a final_model based on a config table.
Here’s the repository structure:

definitions/config.sqlx
| |
Just a fake table with columns and values. It also has a daily_config_update tag.
definitions/notebook_table_to_json.js
Definition of a notebook to export the config table to a JSON file.
| |
Here we are providing query to get data:
| |
notebookConfiguration — add parameters to the notebook:
| |
dependencyTargets- it is a list of objects that describes the full path to the dependencies ITarget - we need it to run the notebook after the config table is updated.tags- notebook tags. So in our case, we want to use the same tag as thedefinitions/config.sqlxto execute them together.
You could check this in the Compiled Graph:

And also we need to provide outputConfig with Dataform repository name and location:
| |
And the path to the JSON file where we should save the result. The path should start from includes and the folder should already exist in the repository.
Ok, the final step is to just publish the notebook:
| |
It’s not execution, it’s a definition. After that, you could see the notebook in the list of actions. You could find them in the list of all actions:
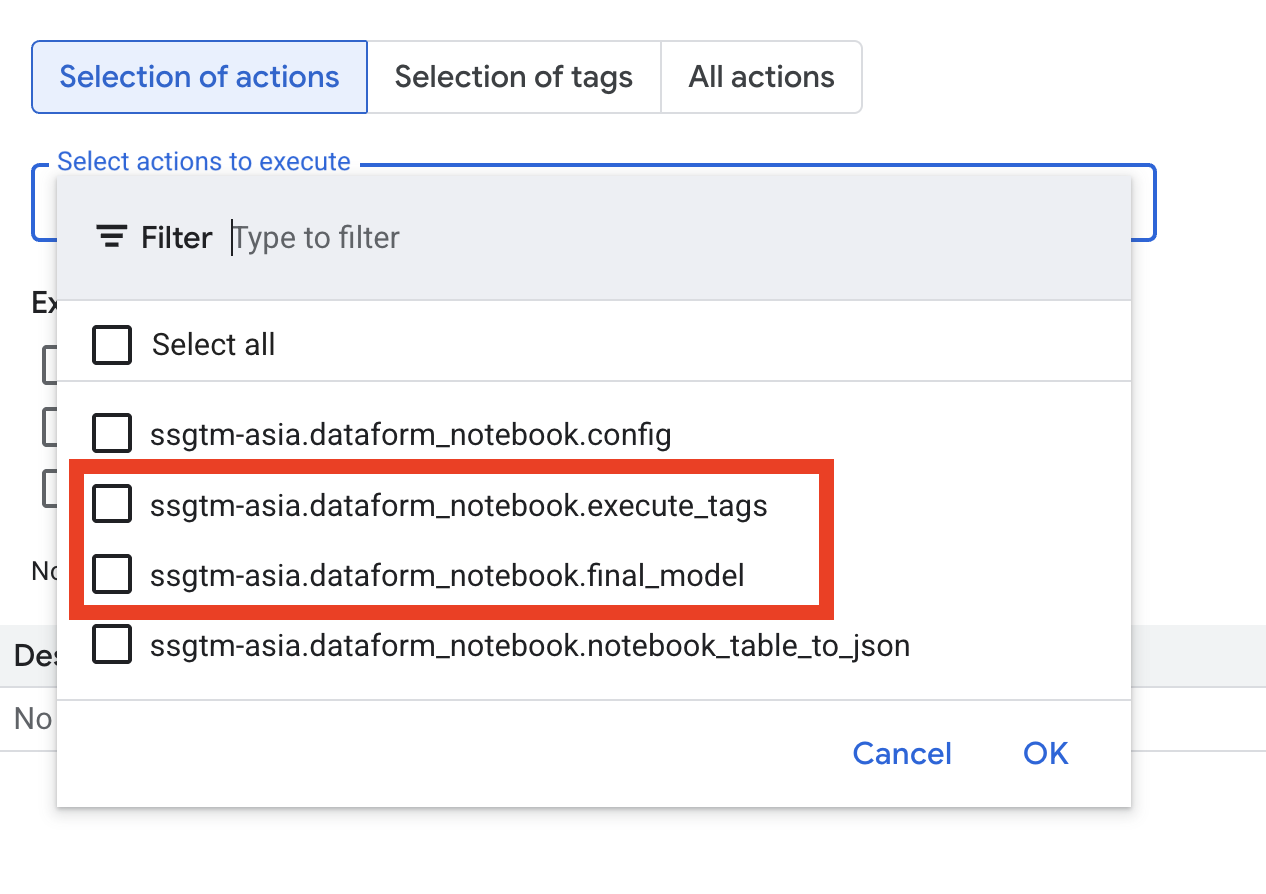
Unfortunately, you don’t see notebooks if you select a tag. I hope it’s a temporary issue, but after you start tag execution, you will see them in the list.
If you run the daily_config_update tag, Dataform should generate config.json. You only need to pull it from the main branch.
So you could use this JSON file to build a new model. For example, like this:
definitions/final_model.sqlx
| |
Super easy, import the JSON file using require and after that, any JavaScript you need.
But as you see, final_model.sqlx has another tag. We can’t use the daily_config_update tag for the final_table because we need to recompile the project to get the latest config.json.
That’s why we use the second package and notebook:
definitions/notebook_execute_tags.js
| |
notebookConfig has the same format as in the dataform-table-to-json package:
| |
Bbut this time dependencyTargets is notebook_table_to_json - previous notebook.
It means after the previous notebook updates the config file, we could run a second notebook to execute the dataform tag. Show the same picture again:
executeConfig describes what repository and what tags to run:
| |
And last step publish the second notebook:
| |
At the end, if you execute daily_config_update, the execution order will be:
definitions/config.sqlxcreate config tabledefinitions/notebook_table_to_json.jsexport config table toincludes/config.jsondefinitions/notebook_execute_tags.jsrecompile the project and executedaily_runtagdaily_runtag executes only one modeldefinitions/final_model.sqlxbased on currentincludes/config.json
And finally, I want to share a few Dataform notebook tricks and tips.
Notebooks
BigQuery UI
The first advice — currently, Notebook development is not fully integrated in Dataform, so it’s much easier to test everything inside the BigQuery interface and after all tests are done, export the ipynb file.
Just an example of a few lines of code - how to export BigQuery data to pandas:
| |
Cleaning
Dataform itself cleans the notebook before execution. But I prefer to also clean all outputs myself before adding them to the Dataform repository, using jupyter nbconvert:
jupyter nbconvert --ClearOutputPreprocessor.enabled=True --inplace *.ipynb
Copy the file content:
pbcopy < ./notebook.ipynb
And paste it in the Dataform UI (if you don’t develop models locally).
Dynamic content
The biggest challenge was how to update notebook content in Dataform before execution. For example, for tag execution, we need to change the tags before executing the notebook.
Finally, I found this solution. I create an empty “hello world” ipynb file and a JSON file with a notebook template notebook_template.json. So I can read the template as a string and replace placeholders with actual values:
| |
And after that, I could initiate a notebook with “hello world” ipynb and update contents with the new_context variable. Something like this:
| |
For notebook configuration, we also could provide ActionConfig.NotebookConfig
Unfortunately, at the moment, filename is required and I didn’t find a way to define a notebook using only the ipynb method. But thanks to open source - it’s possible to spend some time with joy and pleasure reviewing Dataform code to find workarounds.
Final thoughts
Of course, there’s no solution that fits all requirements. This approach is definitely not recommended for huge configurations. And of course, no private or personal data in the Dataform repositories. But I hope these packages could be free and an easy tool in your Dataform toolbox.
I also hope that more and more people start to use Notebooks as part of their Dataform pipelines, as I personally believe it’s a great but undocumented functionality.
If you’re interested in more Dataform content, please follow: Kris, Simon, Johan, Jules, and me on LinkedIn.