
It’s the second post in the series. We will continue working with Google’s GA4 public dataset bigquery-public-data.ga4_obfuscated_sample_ecommerce.events_*. Things become more interesting, or at least I hope so. These are the links to other posts:
- Dataform setup and gentle intro
- Prepare GA4 events and keep them clean - we are here
- Schedule daily updates without Airflow using Cloud Functions
- Setup Dataform notifications (slack, email) and sleep well
- Terraform to rule them all - deploy Dataform in one click (practically)
The Goal
The goal of this article is to show the beauty and flexibility of Dataform. We will prepare GA4 events export, and improve the process step by step using the main Dataform features. If you like the approach you can reuse the code (I’ll add a link to github branches for each step) or just take some ideas and redo everything your way.
Note: You could also use dataform-ga4-sessions package to create Dataform actions (tables) for GA4 recommended and custom events. SQL knowledge is not required.
The basics
We will extract two GA4 events (page_view, purchase) and store them in separate tables.
Every day, we will process the raw GA4 tables analytics_<property_id>.events_<date> and insert new data into the event tables. So all future reports will query these event tables instead of GA4 export tables. This way we can guarantee that we have consistent events in the expected format plus we reduce costs as we will query only the necessary data.
Let’s start with SQL
Page views:
| |
Purchases:
| |
As you see these queries are practically the same.
Few notes:
we use FARM_FINGERPRINT to create
event_id. We will need this ID later to update / insert new data in the event tables later. One note from Taneli Salonen, theevent_timestampfield is the timestamp of the batch in which the event was sent. Even when combined withevent_nameanduser_pseudo_id, there could be cases where the same id is assigned to multiple events. It can be improved by including a custom timestamp parameter in each event. I totally agree with him, andevent_timestampis always on my list of additional event parameters. There is a link to a thread in the Mesure Slack channel with a discussion about this topic.I think it’s always safe to get the date from
event_timestampnot fromevent_date. As DATE(TIMESTAMP_MICROS(event_timestamp)) and CAST(event_date AS DATE FORMAT ‘YYYYMMDD’) could potentially have different values.we add
session_idbased onga_session_idanduser_pseudo_id. Usually we have separate session tables with source / medium / campaign values and we always can join this data to events usingsession_id.Google is afraid that everybody will know that half of its fortune comes from t-shirt sales, which is why they deleted all revenue data from the data set. So we can query only
couponsandcurrency. Of course, in the real scenario, you will savetransaction_id,revenue,taxesand so on.
The next step is to create .SQLX files
/definitions/sources/ga4/page_view.sqlx
| |
The most interesting thing here – the config block. In a previous post we used type table it recreates tables at each run.
Type equals to incremental works more reasonably, it inserts new rows at each run. And it’s exactly what we need. It will run our model everyday, and it will add new rows to the dataform_staging.page_view table. We don’t want to process previous days, as events for these days have already been prepared and stored.
One of the cool Dataform features, it shows you compiled SQL for each action (model). You can find them in the right panel in the Compiled Queries tab. And if you use the increments type you can see two queries (awesome!)
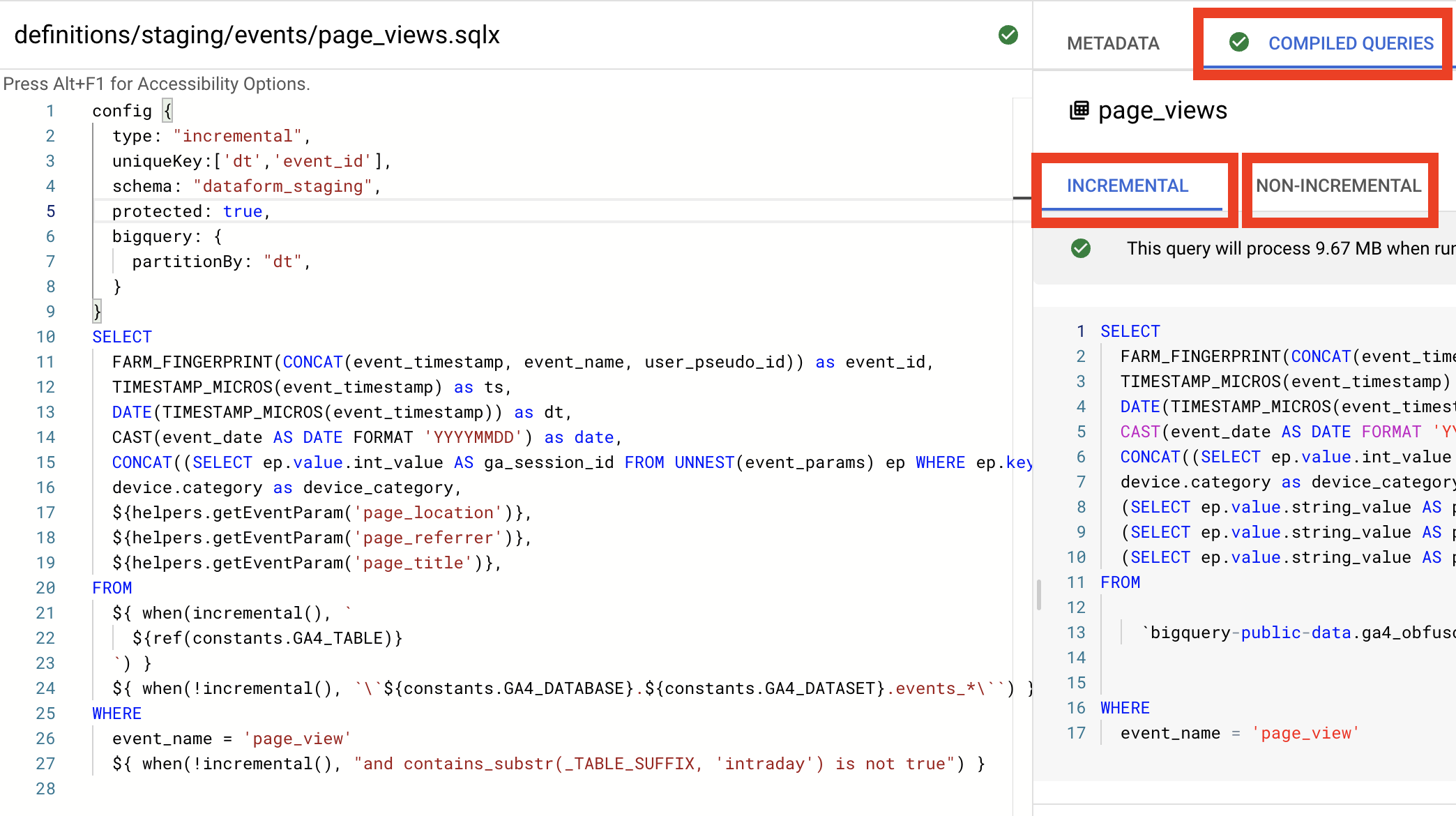
- Incremental - is for the daily run when you only need to insert new data. So in the GA4 case it means we want to process only the last available date table.
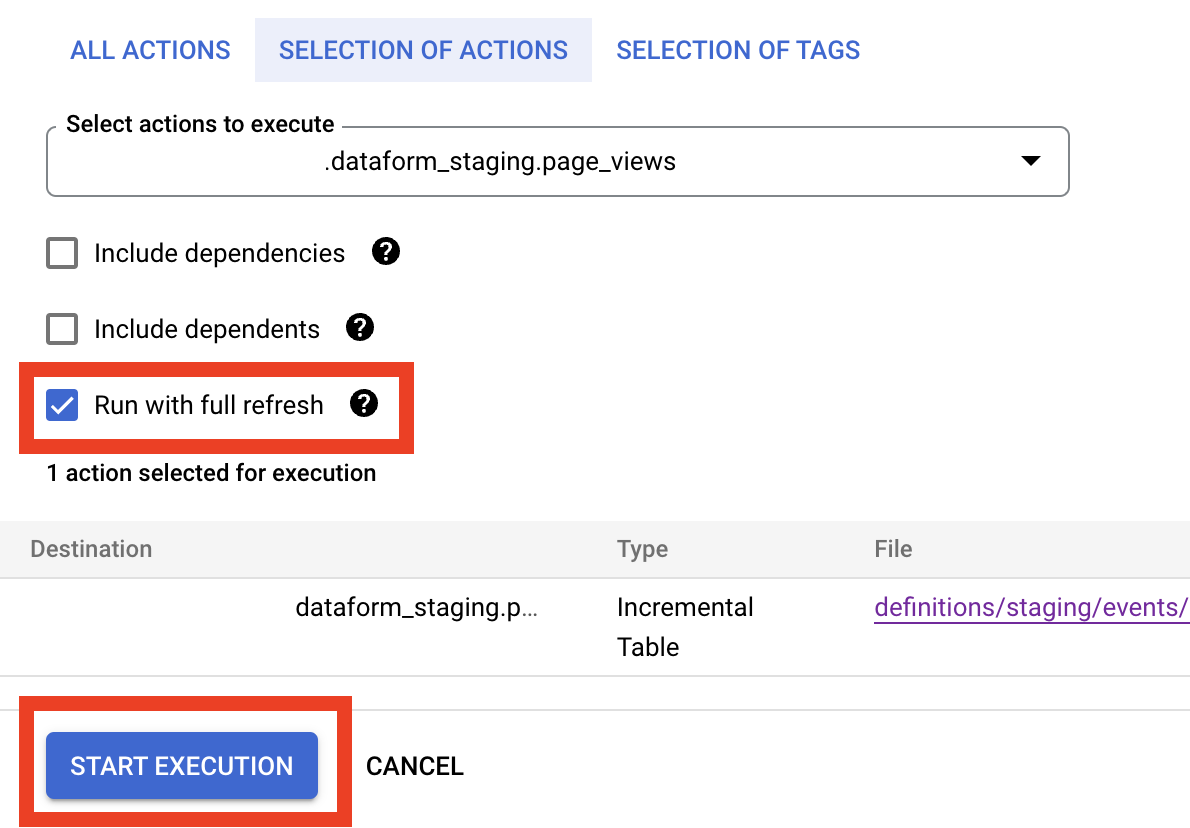
- Non-incremental - this is the first run, to build the table and to process all previous dates. You can also run a non-incremental query if you click on Start Execution, select the action (
page_viewin our example) and tick the Run with full refresh checkbox. (if you forgot or don’t know how to run actions please read the previous post).
In page_view model we also slightly adjusted the query itself.
| |
This line means if built-in method incremental() returns true we will use this table - ref(constants.GA4_TABLE).
Just a short recap - it’s a reference to the model with a name from the GA4_TABLE constant. In our current setup it has a value events_20210131 and you can find the definition for this model in definitions/sources/ga4/declarations.js (again read a previous post for more details)
But for non-incremental (for the first run) we need to query from wildcard table
bigquery-public-data.ga4_obfuscated_sample_ecommerce.events_*
So let’s add one more declaration in definitions/sources/ga4/declarations.js
| |
And now we can reference this table using ref('events_*'). As a result, this code
| |
means:
- for incremental run we query
bigquery-public-data.ga4_obfuscated_sample_ecommerce.events_20210131 - and for non-incremental
bigquery-public-data.ga4_obfuscated_sample_ecommerce.events_*
And one more condition for non-incremental runs:
| |
This way we can guarantee we won’t query intraday tables, unfortunately in the test data set we don’t have intraday tables but later in this post I’ll show you how we can combine daily and intraday data.
You may ask - how to get the last day’s table name? And how to run the action as soon as the table is exported? The answer is very simple, please keep calm and wait for the next post in this series.
So for now everything looks good and we are happy but surprise, surprise Google updates GA4 export daily tables a few times per day. And if we will run incremental models at each time GA4 tables are updated we will insert the same events twice or even more.
And here’s where the beauty of Dataform appears (again): we can add uniqueKey in the configuration block.
| |
And instead of the INSERT statement Dataform generates the MERGE statement which updates existing rows and inserts new.
But from our side no SQL changes are required, we only need to add one line in the config. If you don’t feel the excitement please re-read MERGE statement documentation and imagine having to create all this SQL manually for all events as our grandfathers did.
One more config bonus
| |
This way Dataform will partition tables by dt columns. It means you can reduce cost by specifying only needed dates. And again no SQL magic, only one line in the config.
And one more config parameter
| |
It just blocks run with full refresh, so if you have a huge dataset it’s a good idea to add this to prevent from incidental table rebuilds.
One more comment from Taneli Salonen - there’s also an updatePartitionFilter option for when the uniqueKey is used for doing the merge. It should reduce the query size when it’s looking for those rows that need to be updated. I agree with him that this is a recommended parameter, especially if you have a huge dataset.
Ok the base setup is completed, you can find the code in this branch.
Recap use incremental if you don’t want to rebuild tables each time, use increments with unique keys if your tables are updated a few times and you need merge behavior rather than inserts.
Testing
Let’s test everything. You can easily skip the testing and jump to the next section, it’s only a series of screenshots to keep you more comfortable with the Dataform UI.
Our testing plan is:
- Run all actions
- Get numbers of daily events
- Delete events for one day
- Run incremental update
- Check amount of daily events are they the same as were after first run
- Run incremental update once again
- Check if the numbers are still correct
So go step by step:
- Click Start Execution and select Actions / Multiple actions, in the opening panes select the all actions tab and click the Start execution button.
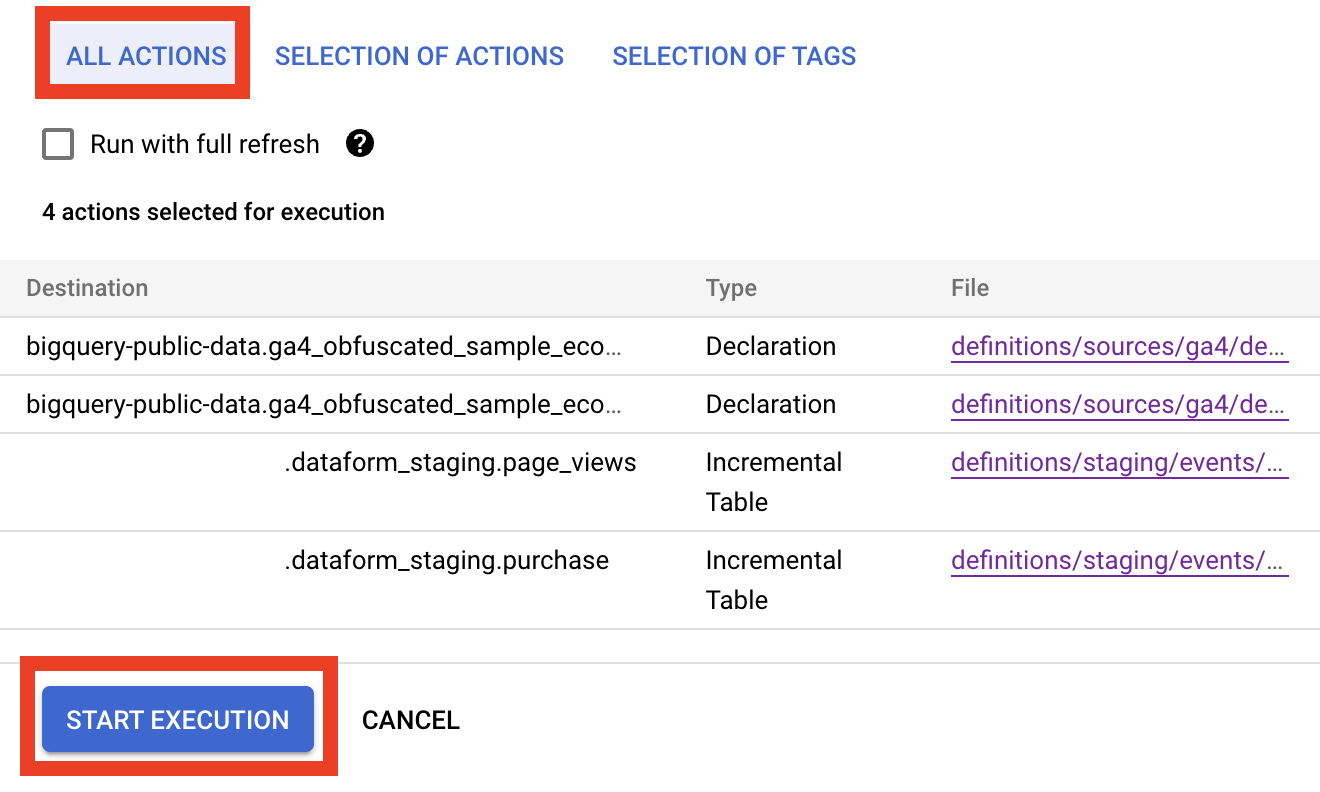
You can click the Details button on the notification popup on the bottom to see executions details

Dataform ““detects”” that tables do not exist and runs non-incremental versions of all actions. After the execution, check in your BigQuery project you should get a new data frame with two tables:

- To get the amount of daily page_views and purchases switch from Dataform to BigQuery SQL Workspace and run this SQL:
| |
Save results for example to Google Sheets to compare them to next steps results.
- To delete data for the last date (2021-01-31) run these 2 queries
| |
After that please run the SQL from the previous step to get numbers of events and to check that you deleted page_views and purchases for 2021-01-31
And now let’s go back to DataForm and run all actions again. We should repeat the same clicks as in step 1, but this time Dataform “detects” that tables already exist and will run incremental queries.
Run a query from step 2 and compare the numbers for 2021-01-31 and previous days with results from step 1. They should be the same.
Repeat step 4, just rerun all Dataform actions again - we do it to manually emulate Google’s GA4 export behavior. I don’t know why but Google updates daily GA4 tables at least two times per day.
Run a query from step 2 one more time and check the numbers. They should be the same again. So our Dataform reruns for the same date changed nothing - we are happy.
Note: If you want a more interesting test you can try to delete or change a few page_views and purchases for 2021-01-31. And in the next step all your changes should be reverted (updated by event_id)
Add data checks
The next step is to add assertions. There are a lot of cases where you potentially could have problems in GA4 data. The most common is data collection changes - developers can change something like dataLayer, CSS selectors, add new functionality which breaks existing logic or even delete GTM itself. So we need notifications (next post), validations and a Hall of Shame for all GTM-deleters.
A few words about “clean data” criteria’s (copy-pasted from one of Dataform tutorials):
- Validity - expected format, all needed fields are set and have expected values
- Uniqueness - don’t have duplicates
- Completeness - no gaps
- Timeliness - should be fresh
- Consistency - no conflict between tables
Dataform provides us with assertions to meet all of these requirements.
The idea of an assertion is very simple - if an assertion SQL returns something - it means we find a problem and assertions fail. Assertions can be built-in - inside the model configuration block or in separate files.
Assertions are easier to understand by examples, let’s define base checks for page_views.
- Validity:
event_idis not empty,page_locationis not null and not equal to (not set) - Uniqueness:
event_idis unique per date - Completeness: we have events for all dates in the range
- Timeliness: the last event is not older than 2 days from now. But Google doesn’t provide fresh data so we should change now to 2022-02-01
- Consistency: we should have at least one
page_viewin a session beforetransactions
Let’s create a new folder inside the event folder for our assertions and add these files:
- /definitions/staging/events/assertions/validation_assertions.sqlx:
| |
Here we have a config block with type assertion and SQL - we will try to get all not valid rows from the page_views table. If the query returns not null the assertions will fail.
- /definitions/staging/events/assertions/unique_assertions.sqlx:
| |
Here we just group by event_id and check if we have more than 1 row with the same event_id
- /definitions/staging/events/assertions/gaps_assertions.sqlx:
| |
The logic is very simple: we generate a table with all days in our date range and join with the amount of page_views for each day. And check if we have a day with 0 or null pageviews.
The only interesting part is a JavaScript block
| |
With js block we can declare functions or variables in any SQLX file, in our sample we declare constants. I think it’s better to move START_DATE to the constants file, and END_DATE to change to max(dt) but I keep it as it is to show js block example.
- /definitions/staging/events/assertions/data_delay_assertions.sqlx:
| |
Usually MAX_DELAY should be 2, but Google stopped refreshing the test dataframe 751 days from now. And now continue updating daily.
- /definitions/staging/events/assertions/consistency_assertions.sqlx :
| |
Here we get all purchases and time of the first page_view, and check if we have purchases before page_view, or purchases without any page_view in the session. And surprisingly we have one such case - a session with only session_start and purchase.
As a next step we can send Slack / Email notifications if any of these assertions fail. But it’s out of scope of the current post, I’m planning to describe how to do it in the following posts.
Not valid event tables
Ok now we can find problems in our data. There are a lot of different strategies for what we can do with non valid events. For the purpose of this tutorial let’s keep clean and dirty events separate, in separate tables.
There are many ways to do it. I think the simplest one is to create a temporary table with additional columns with a validation state. And after that add two models one of them takes only valid events and the second gets only invalid.
A few arguments why to use the temporary table: for cost reduction, this way we query the table with raw data only once and after that work with temporary (smaller) tables. Plus very often we need some additional normalization steps, and we can keep this normalization logic in the model of the temporary table.
Let’s explain this approach by code.
Rename file page_views.sqlx to page_views_tmp.sqlx. SQL will be practically the same, but we change the model’s type to table (I’ll explain this in more detail at the end of this section):
| |
As you can see we changed the config section, reused the SQL from the previous step but added one more column is_valid based on the IF statement. The IF-conditions copied from the validation assertion plus one “fake” rule added - check domain in the list of allowed domains. I added this rule only to have something in the errors table.
Create a new file /definitions/staging/events/page_views.sqlx with this code:
| |
Ok it’s just selecting all rows that are valid from page_views_tmp.
Copy page_views.sqlx, rename it to page_views_errors.sqlx and change the condition from is_valid is true to is_valid is not true.
That’s all but one potential improvement: we can move the validation rules to the JavaScript helper, to have validations for all events in one place. Something like this:
Create includes/validation_helpers.js with this code:
| |
Here we have a JavaScript function that returns SQL statements for is_valid
column. And we can change our page_view_tmp.sqlx like this:
| |
We changed only is_valid definition, instead of SQL we added a beautiful JavaScript function call.
Using the same logic we can prepare purchase events too. I did this exercise, and saved it in the separate brunch: Dataform GA4 events valid/non-valid split.
That’s all, this way we can keep the event tables clean and shiny, and if needed you can add any normalization logic in the temporary tables without pipeline changes.
Not valid event tables with full refresh
Before going to the next section, in a few next paragraphs I want to say more about the process of research and how I choose between variants. It is more like public learning than a finished solution. I’m not sure it will be really helpful so you can safely skip this part.
The current approach has a limitation, it works only for daily updates but for first runs or for full rebuilds you have to change the SQL and use wildcard tables instead of daily tables. Of course you can manually change:
| |
To:
| |
And the problem is solved, but it’s not acceptable, nobody (or at least I) can stand this sort of imperfection of the universe.
At first I try to change temp model from table to incremental type, to use built-in incremental() function and have something like this in code:
| |
Dataform does all the work, and we will query different tables for the first and daily runs.. But incremental models will add new rows every day, but for a temporary tables we don’t need history, we need only one last day.
Dataform can also help, we can delete rows from the temporary table after saving them in the final tables. To achieve this, we can add a post_operation block in the valid and invalid models.
For example for page_view.sqlx add something like this:
| |
But I still don’t like this solution, it creates additional queries (cost) and more importantly it adds one more dependency between models. And someone, who has no idea about this dependency (I mean myself in a three months after deploying) could easily delete this post_operation block and it will break the whole pipeline.
That’s why I feel like a table-type config is better for temporary tables. Because Dataform for table-type models rebuilds tables for each run.
But if we choose a table-type config we still need to understand if it is a first run (does the temp table already exist or not). And based on this condition query either all days or only the last one. Unfortunately incremental() functions always return false for table-type models, so we need to find another solution.
And here’s the beauty of open source software: you can look inside the code and try to understand how the guys behind the tool think and how they solved the same problem.
In query execution screen you can see that for incremental tables Dataform’s gurus use this query to check table exists (and to get its type):
| |
And for the next step they created a procedure which query different tables based on dataform_table_type.
It’s a disaster, I know millions of people in the world create a million SQL procedures daily, and this is even legal, but the whole idea of Dataform it’s to keep models simple and leave all SQL magic to the framework. So I decided to dig deeper in the source code, and tried to find some undocumented features. I found
that they have runConfig property, but I didn’t find how to access itthrough context.
I gave up, and returned to the SQL approach. Again I don’t know an easy way to conditionally query different tables, but we can add some logic in the where statement so at the end I come to this:
First, let’s declare a variable which checks if the temporary table already exists. Add this block in page_view_tmp.sqlx:
| |
With the pre_operations block you can define some logic before the model (action) runs. For example you can define variables or grant permissions.
Inside the pre_operations block we use the native method name() which returns the current table name (only) and the self() method which returns the whole name including the project and dataset.
But we need to query <project>.<dataset>.INFORMATION_SCHEMA.TABLES to check the table. To extract dataset name from self() we can use JavaScript oneliner:
| |
And save it in our include/helpers.js file.
The variable is_event_table is null if the temporary table is not defined, so now we can in both cases query the wildcard table and add conditions on _TABLE_SUFFIX.
Something like this:
| |
As you see, if is_event_table is null (first run) _TABLE_SUFFIX can match any value, if a temporary table exists _TABLE_SUFFIX should equal the value from constants.GA4_TABLE.
But we have to create a JavaScript function which converts events_20210101 (table name) to 20210101 (_TABLE_SUFFIX for this table):
| |
I agree, it’s not the best solution, as we have to delete temporary tables if we want to do a full refresh. But for me these small challenges (when you feel like your solution is far from perfect) is always a great chance to learn something cool or spend a few hours optimizing a 10 second tasks you will run twice in life.
Code for this section: Dataform GA4 events valid/non-valid plus first run support
Intraday events
As I said, unfortunately in Google Public GA4 dataset we don’t have intraday tables, so you have to test in your own projects. But I suppose it’s a rather important aspect of GA4 data processing, so let’s Dataform it.
The simplest approach to merge daily and intraday data can be:
- For the intraday tables we will use models with type
table, with the same SQL as for daily tables (except table names of course) - We will create a view which combines daily and intraday data - and we will use this view in all reports needing fresh data
- For intraday tables we will create different triggers for example hourly, and for each run intraday tables will be deleted and inserted again (it’s a default behavior for models with
tabletype)
This way we will have a view with fresh data and shouldn’t have duplications. As Google deleted events from intraday tables when they copied them to daily tables.
It will be fast. First let’s update our sources, add to /definitions/sources/ga4/declarations.js this code:
| |
After that we can query all intraday tables (usually its a two tables for today and yesterday) like this:
| |
Second, create /definitions/staging/events/page_view_intraday.sqlx:
| |
The same SQL code as for page_view_tmp.sqlx but without any validation or black magic.
And let’s create a view with an intriguing name page_view_view.sqlx:
| |
As you see in the config block we define type view, and SQL is just union all of two tables plus one helper column with an event type.
That’s all we will create hourly triggers in the next post.
But for now you can have a look at the final code here: Dataform GA4 intrafay events
One final note if you are working with wildcard daily tables don’t forget to filter intraday table like this:
| |
Declare events tables using JavaScript
Everything looks more or less good except that we repeat a lot of code many times and have five models for each event. And if we need to prepare dozens of events there are too many copy-pastes. It always smells like refactoring something near here.
So in this part instead of five .sqlx for each event we will try to create one JavaScript file with a declaration for all tables, and one configuration file for all events. And if later we decide to process a new event, all we need to do is add a few lines to the config file. I hope you are excited.
A little bit of the Dataform “theory”. We can define table using publish method.
For example this code:
| |
Will create a table with a name example, based on this SQL:
| |
Important note: in the publish function we should use the context object, and instead of built-in functions like ref(), self() and so on we should use context methods like ctx.ref(), ctx.self() and so on.
We also can add config block like this:
| |
Let’s recap. To add a table model dynamically, call publish with a table name and a query method which returns SQL code for the model.
Learning by doing saves the world, so let’s start with the simplest model, and change page_view_view.sqlx (read: delete the sqlx file first) to JavaScript declaration.
Create file definitions/staging/events/declarations.js with a code:
| |
What happened here:
publish("page_view_view")- call publish and set table name.config({type: "view",schema: "dataform_staging"})- add config to the model.query(ctx => … )- set the model SQL, changing ref() to ctx.ref()
Shouldn’t be too scary
Ok next step, do the same for page_view_intraday. Delete page_view_intraday.sqlx and add this code in /definitions/staging/events/declarations.js:
| |
Absolutely the same, set config type to table and copy SQL code inside the query method changing ref() to ctx.ref()
And now something interesting delete page_view_tmp.sqlx and add this code in the declaration file:
| |
The interesting part here is:
| |
Google forgot to mention preOps and postOps functions but we can find them in the original Dataform documentation
And a small note from MDN: to escape a backtick in a template literal, put a backslash () before the backtick.
And finally page_view and page_view_errors models, again delete .sqlx files and add this code to the declaration:
| |
And the same for page_view_errors. You can get our current state in this brunch: Dataform: JavaScript model declaration for GA4 event
For now it doesn’t look much better. Instead of five small and simple .sqlx files we created one long and a bit heavy JavaScript, but don’t jump to conclusions, our refactoring only just began.
Next, let’s take a closer look at SQL for the event_table, here we have 3 types of columns:
event_id,dt,ts,session_id- base columns we decided to extract for all events (not only forpage_view)page_location,page_referrer,page_title- we unnest these columns form event_paramsdevice.category- this column we get from raw table columns
We can move these params to the configuration file, and rebuild all requests based on this file. But there’s no need to add these columns: event_id, dt, ts, session_id - as we want to add these params for all events, so we will keep them in the query itself.
Let’s create includes/events_config.js with this code:
| |
Here we define a list of objects (one object for each event), each of them has:
- eventName - for example
page_view - eventParams - list of parameters we unnest from event_params column of GA4 daily (raw data) tables
- params - list of columns we query from the raw table
And now we can use this config in definitions/staging/events/declarations.js:
At first let’s declare table names for each event in the config:
| |
So we can change hard coded table names to variables. For example for valid events table:
| |
It’s absolutely like it was before (on the last step) except for the table name.
The same for the error table and for the view. But for the intraday table we also have to generate list of columns:
| |
As you see we keep event_id, ts, ds and session_id. But for other columns we use two helpers passing params and eventParams from config:
| |
And here is the helper’s definition:
| |
getTableColumns generates strings like:
device.category as device_category,
And the getTableColumnsUnnestEventParameters use getEventParam helper method to generate something like this:
${helpers.getEventParam('page_location')},
I hope you are still with me, keep calm, that’s practically all for this step. So at the end we have new /definitions/staging/events/declarations.js with this code:
| |
And this is much better. As for now, if we need to add new events we don’t need to change the JavaScript declaration, only update the configuration file.
For example, if we want to add purchases, first delete all five purchase-related .sqlx files and add these lines in includes/events_config.js:
| |
And if you return to definitions/staging/events/declarations.js and check the list of COMPILED QUERIES, you will see all page_view and purchase tables.
Bless DataForm again and again. That’s super cool. We don’t need to copy and paste practically the same tables for each new event, we can only add a few lines in the config and all models will be generated.
You may have a look at the final code for this step in this branch: Dataform GA4 events based on configuration file
Reduce amount of bites billed
Maybe things become slightly complicated but now we have a configuration file and could generate models for all GA events we need. But configuration files could give us even more flexibility. For example if you have a rather huge data source, consisting of dozens of GA4 events and you really care about money that you spend on queries you could optimize requests a little bit further.
At the moment we query all events from the raw daily table, but potentially we can add one more step in our pipeline - generate a temporary table with only the events and columns we need. This temporary table will, in most cases, be much smaller than the raw daily table. And all our event models would query this temporary table instead of a daily one. Less bytes billed - lower the final bill.
And thanks to the configuration file we know exactly what events and columns we need.
This part I leave without code yet. But if somebody reached this point and is interested in code samples, please message me on LinkedIn. I’ll add one more branch to the repository.
Final thoughts
In short that’s all I wanted to say about GA4 events processing in Dataform. Again please treat this post more as the starting point of your own DataForm journey than as a production ready solution for all cases. But still I hope it will be helpful, at least it should answer the question - why should I use Dataform (or similar but not natively integrated tools).
The next post about Dataform will be much shorter (I promise). I’m going to describe how to trigger hourly runs and run pipelines as soon as the GA4 table is ready. Cloud Functions and Python will be mentioned.
Please message me LinkedIn if you prefer a different approach to preparing GA4 events using Dataform or if you think this post is damn good.
PS. A special thanks to Max Poirault for his patience, he asked me about this post on LinkedIn, and I published it practically immediately (in 4 weeks) after his message.