
This post is part of a series of Dataform posts. I assume you already read the previous posts and are ready to trigger your GA4 data pipelines.
- Dataform setup and gentle intro
- Prepare GA4 events and keep them clean
- Schedule daily updates without Airflow using Cloud Functions - we are here
- Setup Dataform notifications (slack, email) and sleep well
- Terraform to rule them all - deploy Dataform in one click (practically)
The Goal
In this post I’ll show how to run Dataform for these two cases:
- As soon as GA4 tables are ready
- Hourly (based on Google Cloud Scheduler)
To make things a bit more interesting I’ll add a few additional requirements for GA4 daily tables trigger:
- Get a table name and process only models related to the updated table
- If we have more than one GA4 dataset, execute only models from the same dataset as the updated table.
- Don’t use Airflow or Google Workflow. They’re great tools, but we don’t need any additional orchestration tool for this simple case, as Dataform manages dependencies (thanks to ref). So we need only to run the flow at the right time.
Note. Unfortunately Google doesn’t update GA4 test dataset. But we will prepare everything and be ready to process new Google Store sales, not a single Google t-shirt will slip past us. But of course, we can do a few manual tests while waiting..
The plan
We will first set dataset_id as tags for each model. Then on GA4 table update, we will generate a pubsub event with dataset_id and table_name. And based on this event, start Dataform execution with tags value equal to dataset_id and pass table_name as a configuration variable.
For example, imagine we have GA4 property with an ID equal to 123456, the data from this property is exported to the analytics_123456 dataset. Our plan is:
- For all models like
sessions.sqlx,page_view.sqlxetc.. we set tags value as analytics_123456; - For daily export Google creates a new table events_22220101;
- We subscribe to this event, execute Dataform actions with tags equal to analytics_123456, and pass table name events_22220101 as a variable.
Thus when Google exports GA4 data for one property we will run only actions for this specific property.
Preparatory stage
In this post, I will use code from the previous post and a separate repository with cloud functions.
But before we can start playing with Cloud Functions we need slightly change Dataform actions – add tags and global variables.
Rename models
First I usually rename all files and models to something dataset-specific.
For files, I add GA4 property ID at the end. For example, I rename sessions.sqlx to sessions_123456.sqlx where 123456 - GA4 property ID. But for this tutorial, we use only one test dataset so I keep the file names as it is.
The next step is to rename all the models. In the definitions/staging/events/declarations.js add a postfix for all constants with table names:
const eventName = eventConfig.eventName_sample_ecommerce;
const eventTbl = eventConfig.eventName_sample_ecommerce;
const eventTempTbl = `${eventConfig.eventName}_tmp_sample_ecommerce`;
const eventErrorsTbl = `${eventConfig.eventName}_errors_sample_ecommerce`;
const eventIntradayTbl = `${eventConfig.eventName}_intraday_sample_ecommerce`;
const eventView = `${eventConfig.eventName}_view_sample_ecommerce`;So for each GA4 property I create separate .sqlx or .js files, and in all files add GA4 property ID at the end of all models. And after all models execution, in the dataform_staging dataset, we will have tables like sessions_<property_id>, page_view_<property_id>, etc. for each GA4 property.
Add tags
In Dataform we can start execution with a tag, in this case, we will run only actions having this specific tag, and can control which models to execute.
So in definitions/staging/events/declarations.js we need to find all config blocks and add tags, something like this:
.config({type: "table",schema: "dataform_staging",tags:["ga4_obfuscated_sample_ecommerce"]})We also add ga4_hourly tags to intraday tables and views.
.config({type: "table",schema: "dataform_staging",tags:["ga4_hourly", "ga4_obfuscated_sample_ecommerce"]})To check you did everything correctly you could rerun all actions by tag.
Click on Start Execution button, hover over Tags menu, and click on ga4_obfuscated_sample_ecommerce.
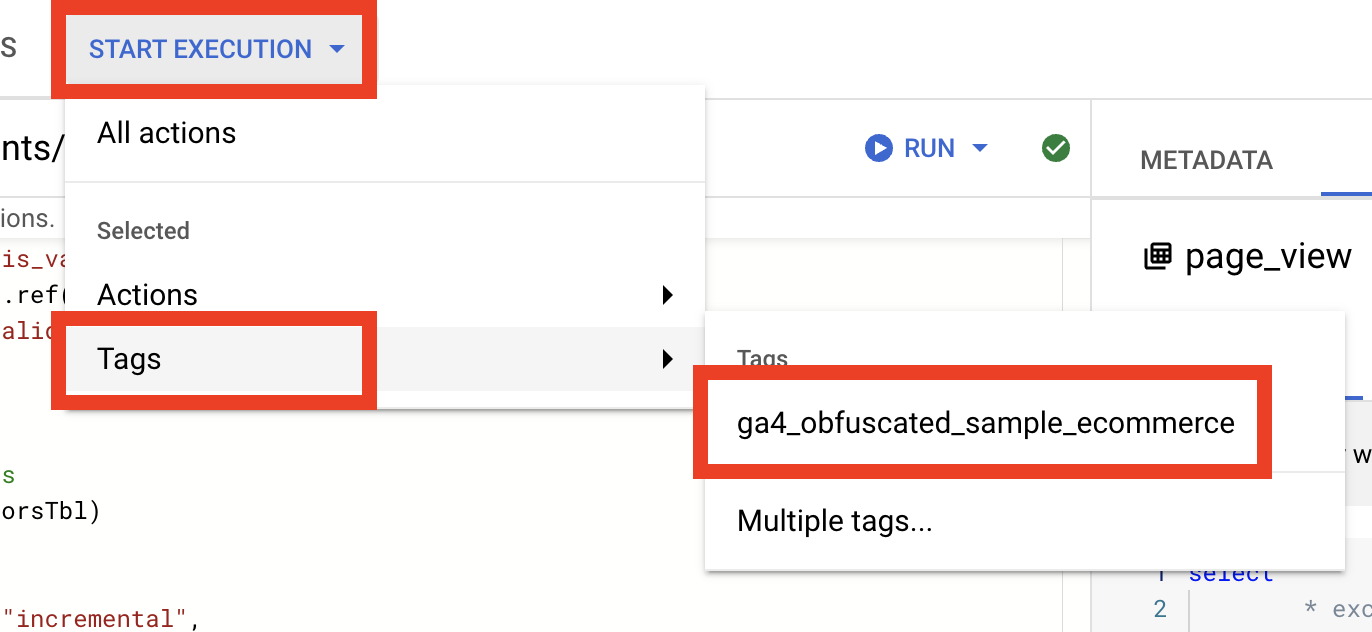
You should see the right panel with all our models, and of course, click to Start Execution to check everything ready for automation.
Move the table name to the global config
And the last preparation step – is moving constant GA4_TABLE with a last-day table name from includes/constants.js to global config dataform.json.
When we run Dataform by API, we can set a new value for the configuration variable. And we will change GA4_TABLE to the name of the updated table.
But for now, delete GA4_TABLE from includes/constants.js.
const GA4_DATABASE = 'bigquery-public-data';
module.exports = {GA4_DATABASE}And add it to dataform.json
{
"defaultSchema": "dataform",
"assertionSchema": "dataform_assertions",
"warehouse": "bigquery",
"defaultDatabase": "cafe-assistant-295900",
"defaultLocation": "US",
"vars": {
"GA4_TABLE": "events_20210131",
}
}So we add vars key and define GA4_TABLE value.
And one more time, thanks to Dataform! In the interface in the files tree you will see compilation errors:
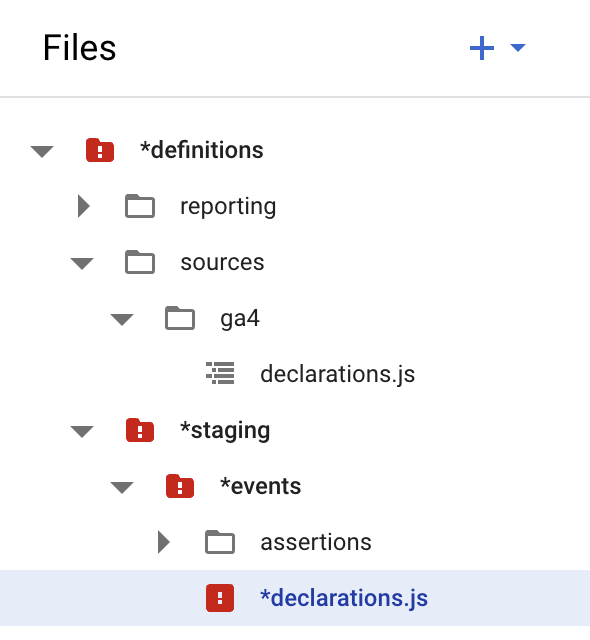
It shows which files use the deleted variable, so we can quickly fix it. In definitions/staging/events/declarations.js change constants.GA4_TABLE to dataform.projectConfig.vars.GA4_TABLE.
In our tutorial, we have only one dataset, but if you have more than one dataset you need also to specify the dataset name in all your refs functions. Because overwise you will have a name conflict – more than one model with the same name.
So change:
${ctx.ref('events_*')}
To
${ctx.ref(constants.GA4_DATABASE, dataform.projectConfig.vars.GA4_DATASET, "events_*")}
In our case, we also set database values (constants.GA4_DATABASE), but usually, we query data from the same project so you don’t need to specify a database.
Ok, and we need to make the same changes in definitions/sources/ga4/declarations.js.
Good news everyone, we are ready to trigger our project.
You can see the final state here: Dataform models with tags for daily updates
Trigger Dataform on GA4 table update
Implementation steps
The process will take a few steps:
- Add logging sink on GA4 tables update, the sink will generate Pub/Sub event on table update;
- Create a cloud function that will subscribe to the event from the previous step, extract the dataset and table name from the event, and generate a new Pub/Sub event with parameters needed to run Dataform execution;
- Create cloud function to trigger Dataform based on previous Pub/Sub event;
Yes, I added one more step. We could easily combine the last two into one. But later we will need to execute Dataform based on Google Scheduler, and the format of incoming events will differ. That’s why I added the second step to extract the table, and dataset names and generate the new pubsub events with data in “prepared format” to run Dataform.
As another benefit, you can add more than one subscriber to the GA4 table update event. For example, notify an external system, send slack messages, or create a corporative gambling service and take bets on Google updates data before 12 or later.
Init gcloud configuration
For all these steps I will use gcloud CLI. The most important reason - everybody in the marketing department will know you are a developer because “he uses these black windows”, and second we will reuse the same commands later for the automation.
I’m pretty sure that you have already installed the gcloud. But let me mention these handy little commands to switch between projects. If you already use gcloud configurations please skip this part.
To create a new configuration with the name dataform run this command:
gcloud config configurations create dataformThe new configuration will be created and activated, now we should init it:
gcloud initThen it asks you to pick the next step, select 1:
[1] Re-initialize this configuration [dataform] with new settings.
Then it asks you to choose or log in to an account, if it’s your first configuration you have to log in.
Then you have to choose or create a project and select an existing one with a Dataform code.
Finally, it will ask whether you want to set a default zone for your project.
Congratulations, your first configuration is created. Now you can easily switch between configurations, like this:
gcloud config configurations activate [configuration name]Or lists all existing configurations:
gcloud config configurations listSo you don’t need to specify a project in your gcloud commands and could easily get the project settings.
For example Project ID
gcloud info --format='value(config.project)'We will use Environment Variables in our gcloud commands. With them, it will be easier to reuse these commands between projects.
Let’s define a few variables:
export project_id=$(gcloud info --format='value(config.project)')
export repository_id=dataform-ga4events
export region=us-central1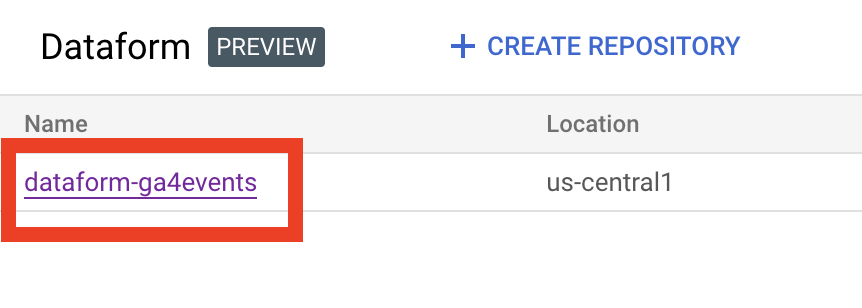
repository_idis the name of your Dataform repository (not your github repository) you can get it from the page on the screen above.regionis the default Dataform region, from the screenshot above you could also get needed location. We will use this location for all Google Cloud services we enable later.
To check you did everything right, you could run echo command:
echo ${project_id}Create Pub/Sub topics
According to our plan we will need two Pub/Sub topics, let’s create them. First, define variables with their names:
export ga4_table_updated_topic=ga4-table-updated-topic
export dataform_run_topic=dataform-run-topicAnd run these gcloud commands:
gcloud pubsub topics create ${ga4_table_updated_topic}
gcloud pubsub topics create ${dataform_run_topic}Open Pub/Sub page of your project and check the list of topics, you should see something like this:
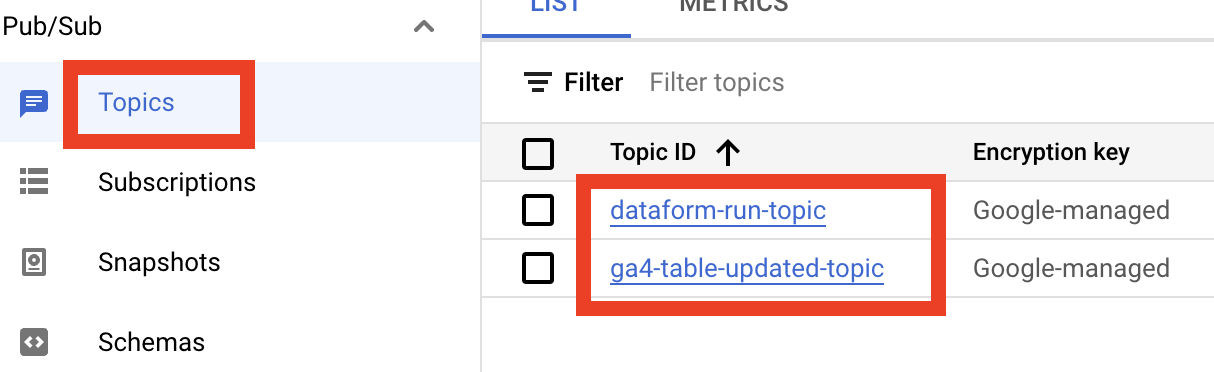
Later we will return to this page to check that we grant all required permissions.
Create logging sink
This is the sad part of this tutorial, the hopeless one. As Google doesn’t update its test dataset. So if you want to test this part you have to change Google’s dataset to your real GA4 dataset.
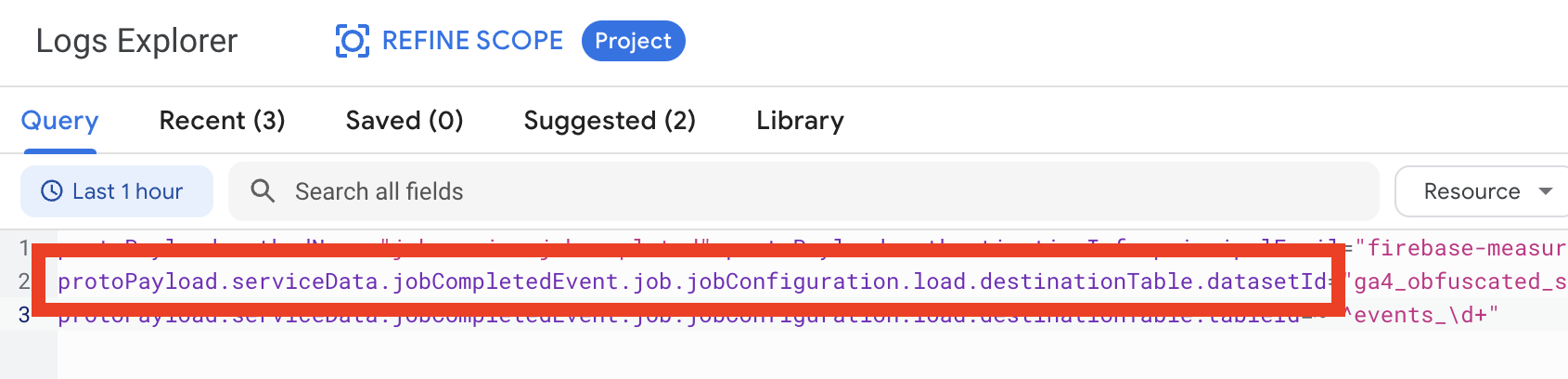
Before creating a sink, let’s find logs record about GA4 daily table creation. Open the Logs Explorer and try to use this query:
protoPayload.methodName="jobservice.jobcompleted"
protoPayload.authenticationInfo.principalEmail="firebase-measurement@system.gserviceaccount.com"
protoPayload.serviceData.jobCompletedEvent.job.jobConfiguration.load.destinationTable.datasetId="DATASET"
protoPayload.serviceData.jobCompletedEvent.job.jobConfiguration.load.destinationTable.tableId=~"^events\_\d+"As you see here we filter by principalEmail. BigQuery Export should always use this account firebase-measurement@system.gserviceaccount.com
Please also change DATASET to your GA4 dataset name, something like analytics_311287033. And because all daily tables have names like this events_20230415 - we can use this regexp ^events_d+ for the table_id.
So copy-paste the query to the Logs explorer change the date range from Last 1 hour to Last 2 days, and click Run query:
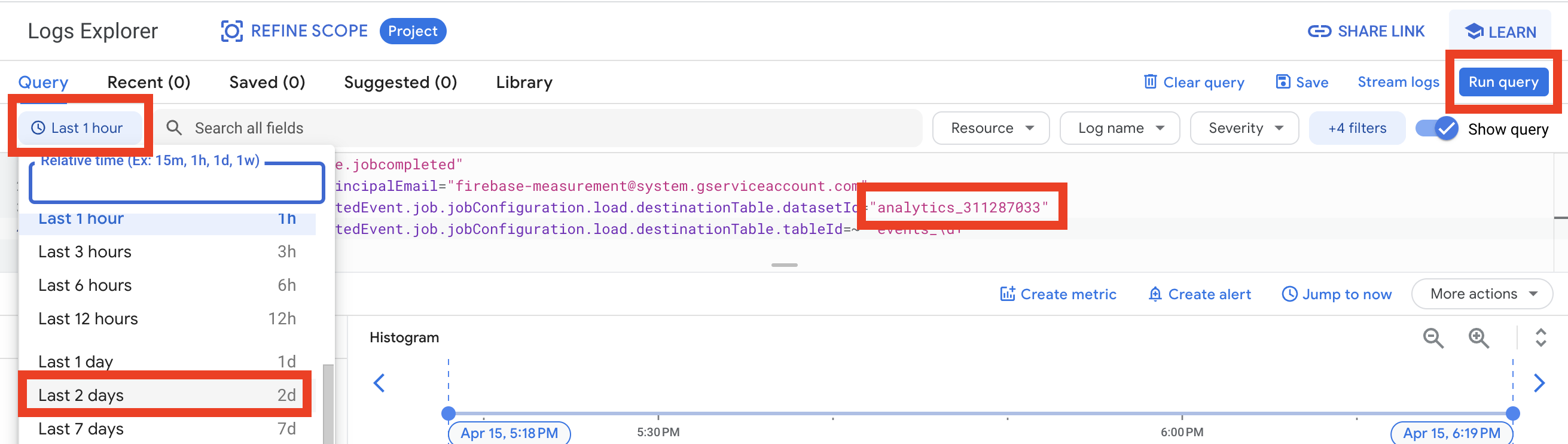
You should see a few records. Select any row, click on Collapse nested fields button, and review the log data.
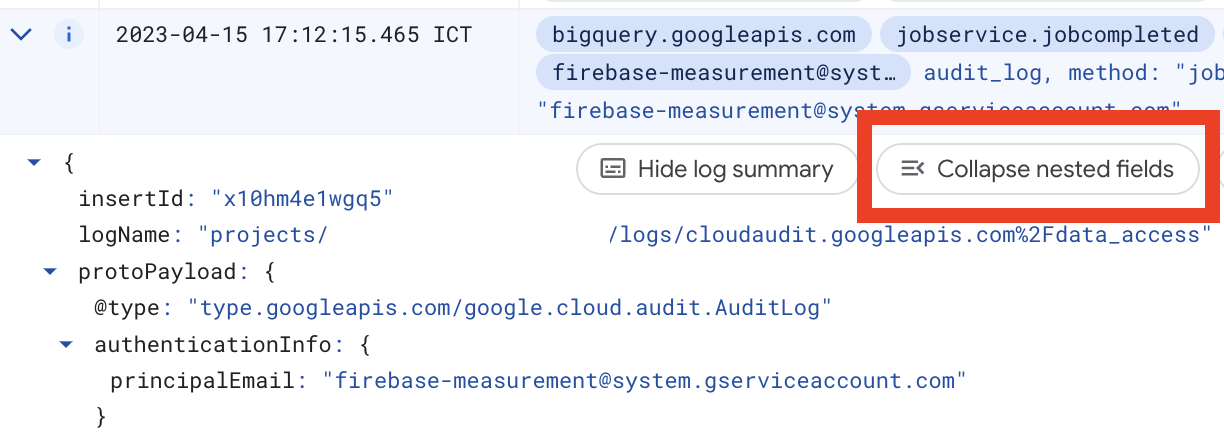
And also you can notice that sometimes we have more than one event per day, but we were prepared and in the previous post defined increments Dataform models with the unique keys.
One small note, In this query we can trust, as it was suggested by Simo in his article How Do I Trigger A Scheduled Query.
And now we are ready to create a logging sink. To create a sink we should set the:
- Sink name
- Sink destination
- Log filter
For pub/sup destination we will define this string:
pubsub.googleapis.com/projects/${project_id}/topics/${ga4_table_updated_topic}And for the filter we could use the query from above. And define it in a variable:
export sync_filter="protoPayload.methodName=\"jobservice.jobcompleted\" protoPayload.authenticationInfo.principalEmail=\"firebase-measurement@system.gserviceaccount.com\"
protoPayload.serviceData.jobCompletedEvent.job.jobConfiguration.load.destinationTable.datasetId=\"${dataset}\"
protoPayload.serviceData.jobCompletedEvent.job.jobConfiguration.load.destinationTable.tableId=~\"^events*\d+\""Just notice we use a dataset variable in the filter’s variable definition and also escape all quotes by slashes.
Ok, go ahead and create a sink:
gcloud logging sinks create ga4-table-updated-sink \
pubsub.googleapis.com/projects/${project_id}/topics/${ga4_table_updated_topic} \
--log-filter="${sync_filter}"You will get this warning:
Please remember to grant
serviceAccount:p855840598401-539779@gcp-sa-logging.iam.gserviceaccount.comthe Pub/Sub Publisher role on the topic.
We are not going to disappoint Google and will grant permission in two steps. First, get the writerIdentity account:
gcloud logging sinks describe --format='value(writerIdentity)' ga4-table-updated-sinkHere we use describe commands together with format. It’s a handy trick we will use often not only for sinks. Remember ga4-table-updated-sink - the name of the sink from the last step.
And we can set this value to a variable like this:
export sink_writer_identity=$(gcloud logging sinks describe --format='value(writerIdentity)' \
ga4-table-updated-sink)The second step is adding the permission:
gcloud pubsub topics add-iam-policy-binding ${ga4_table_updated_topic} \
--member="${sink_writer_identity}" --role="roles/pubsub.publisher"As usual, let’s check the result. On the Log Router you should get something like this:
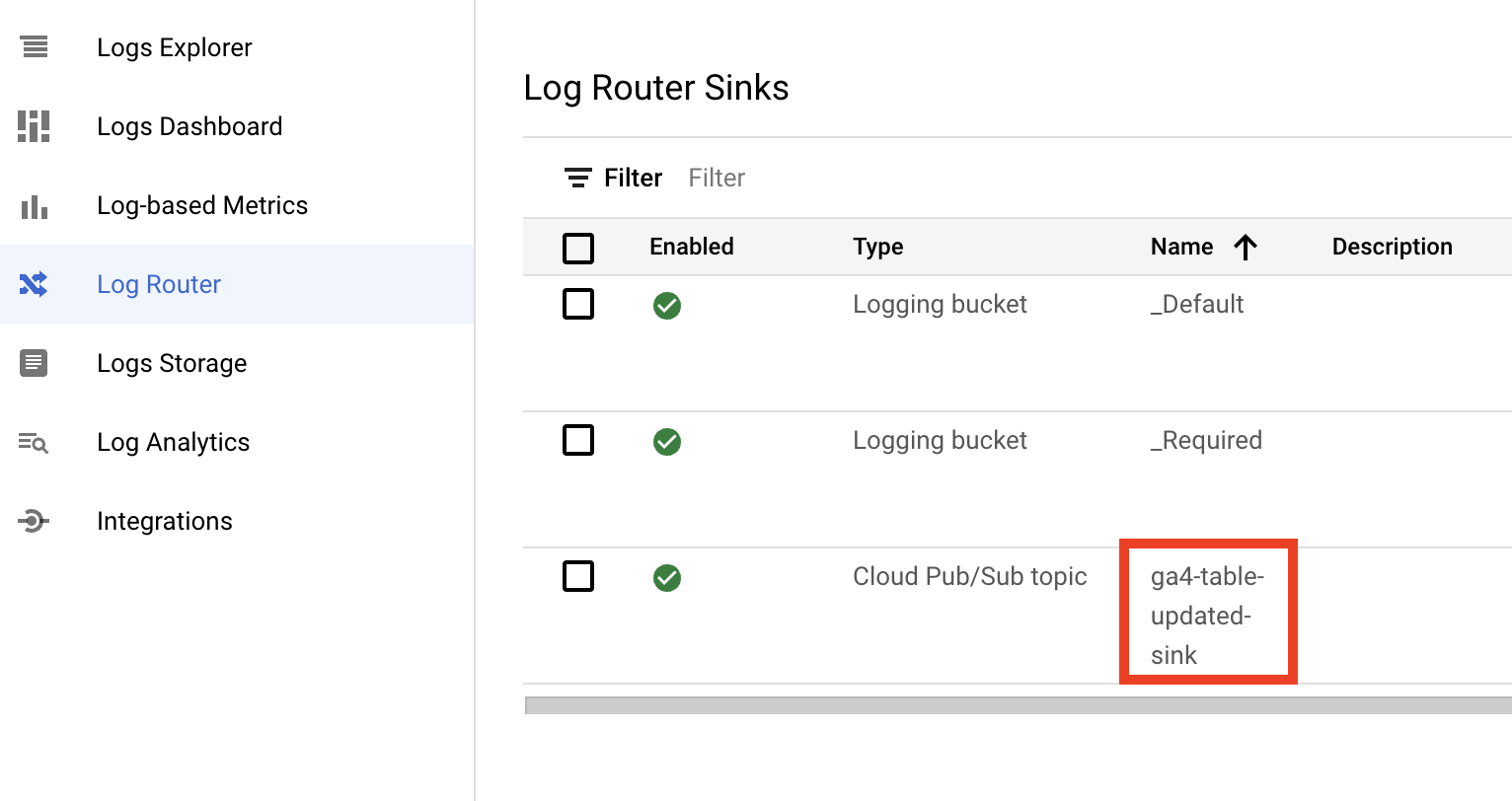
Here are a few default routes, plus our sink. You could click on three dots for this route and click View sink details to check the destination and the logging filter. Or you can click Troubleshoot sink to test the filter in the Log Explorer.
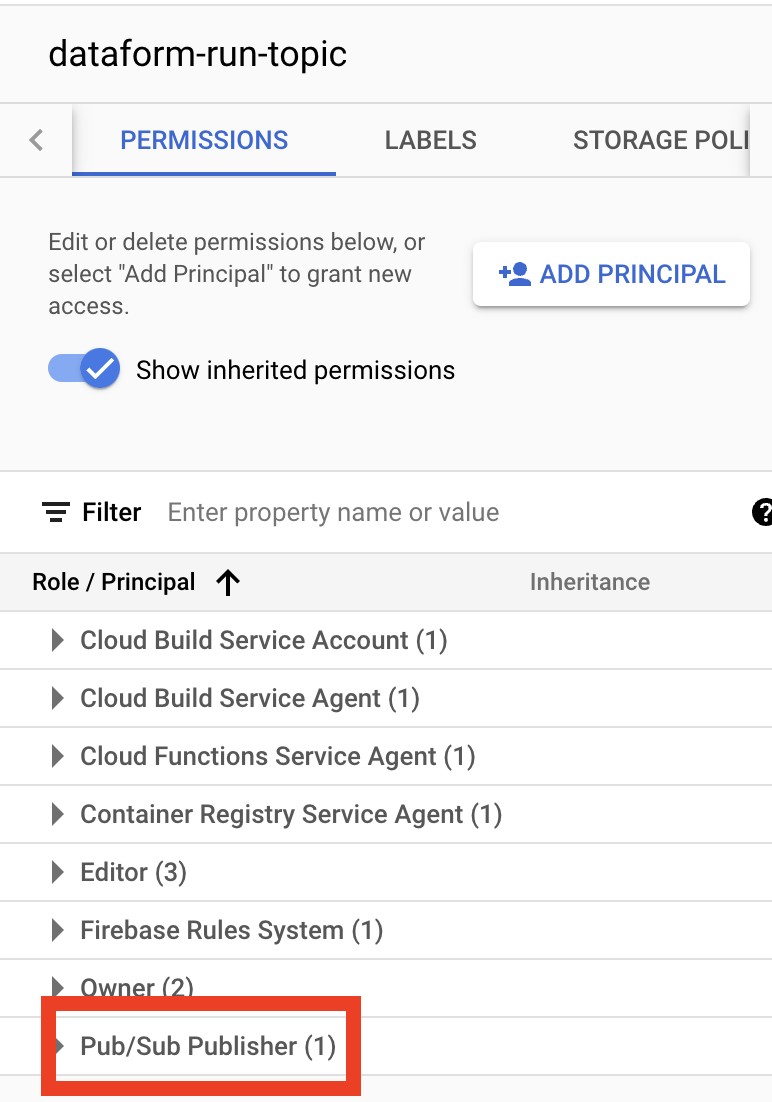
Ok, next go to the Pub/Sub Topics page, click on ga4-table-updated-topic, and in the Permissions tab, open Pub/Sub Publisher Role and check the accounts list:
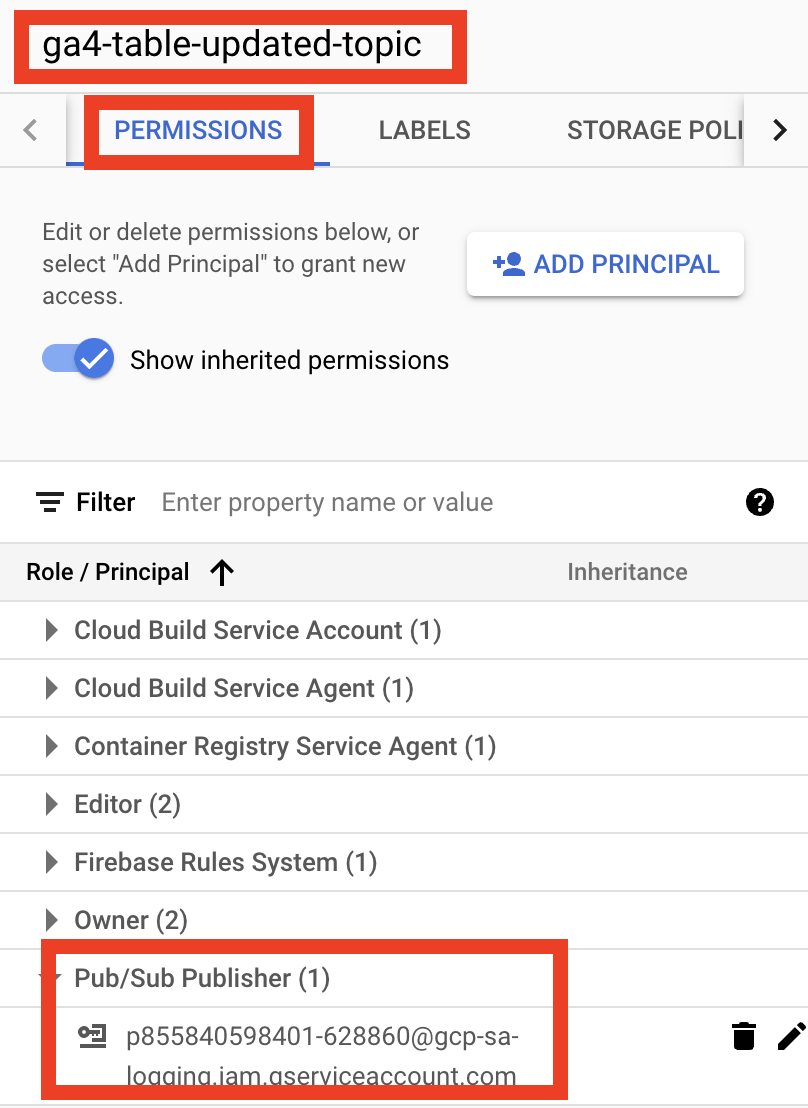
If you don’t see this panel click on Show info panel button in the top right corner:

Cloud function for sink events
The next step is to create the function to extract all needed information from the log and generate a new pubsub event.
Clone repo with the functions:
git clone https://github.com/ArtemKorneevGA/dataform-cloud-functions.gitGo to the function folder
cd ./ga4-table-updated-pubsub-event-funcLet’s review the function code before running it. Have a look at the main.py
All the logic is in the main function. Here we get log_entity we sent from the sink:
| |
In the second step we prepare the config
| |
We get last_event_table, dataset_id from log_entry. As you notice we used the same “path” log_entry["protoPayload"]["serviceData"]["jobCompletedEvent"]["job"]["jobConfiguration"]["load"]["destinationTable"]["datasetId"] as we use in the sink filter:
And the last step we create a new pubsub event:
| |
We get pubsub client, and generate the topic_path based on project_id and environment variable. And send the config variable to this topic.
The function expected these environment variables:
- project_id
- region
- repository_id
- git_commitish
- dataform_run_topic
We already define all of them in the previous steps. So we are ready to publish the function, using gcloud functions deploy command with trigger-resource and trigger-event for the pubsub events generated by the sink. And pass all needed variables using set-env-vars parameter. Like this:
gcloud functions deploy ga4-table-updated-pubsub-event-func --max-instances 1 \
--entry-point main --runtime python39 --trigger-resource ${ga4_table_updated_topic} \
--trigger-event google.pubsub.topic.publish --region ${region} --timeout 540s \
--set-env-vars project_id=${project_id},region=${region},repository_id=${repository_id},git_commitish=${git_commitish},topic_id=${dataform_run_topic}If it’s the first cloud function in your project you will see:
API [cloudfunctions.googleapis.com] not enabled on project [ID]. Would you like to enable and retry (this will take a few minutes)? (y/N)?
Type Y and wait for a few minutes while the function is deploying.
You could check the functions list, the new function should be green:

One more important step we should grant our function permission to write in the pubsub topic.
First, we need a function’s service account. And again describe command in the rescue:
gcloud functions describe --format='value(serviceAccountEmail)' \
ga4-table-updated-pubsub-event-funcSet the environment variable:
export function_service_account=$(gcloud functions describe \
--format='value(serviceAccountEmail)' ga4-table-updated-pubsub-event-func)And set the permissions as we did for the sink, but this time for the function’s service account:
gcloud pubsub topics add-iam-policy-binding ${dataform_run_topic} \
--member="serviceAccount:${function_service_account}" --role="roles/pubsub.publisher"Open the dataform-run-topic page and check who has Pub/Sub Publisher role.
Everything looks good, but unfortunately we can’t test this function as Google doesn’t update GA4 dataset.
Cloud function for Dataform run
Dataform API documentation (or its absence) makes this part the most interesting.
But thanks to open source the World is such a beautiful place to live. We can look inside the Airflow module for Dataform and use their code as a starting point, plus add a few missing features.
We will run Dataform in two steps:
- create_compilation_result
- create_workflow_invocation
In the first step, we pass:
git_commitish- the branch name, usually amain. This way we could do all our experiments in separate dev branches and push tested results in themain.GA4_TABLE- a configuration variable with the updated table name.
In the second step, we invoke compilation results and pass the tags name equal to dataset_id. If you remember, later in definitions/staging/events/declarations.js file, we set tags:[“ga4_obfuscated_sample_ecommerce”]. As the tags are the same, we will execute all the models from the file.
If you have multiple GA4 datasets in one project, as soon as one of the GA4 tables is updated we will run Dataform models only for one project (based on the tags), and actions for other datasets won’t be executed.
Let’s review the code. Go to the second function folder:
cd ../ga4-table-updated-dataform-run-func/In the main.py again first, we prepare the incoming event:
| |
Then create compilation config (compilation_result), and set branch name and global variables from the event:
| |
And create the compilation:
| |
Further, we pass tags in the invocation config
| |
And create invocation:
| |
Thanks to Airflow one more time.
And finally, we can deploy our function:
gcloud functions deploy ga4-table-updated-dataform-run-func --max-instances 1 \
--entry-point main --runtime python39 --trigger-resource ${dataform_run_topic} \
--trigger-event google.pubsub.topic.publish --region ${region} --timeout 540sAgain we use gcloud functions deploy command, and set ${dataform_run_topic} as trigger-resource.
Let’s check the list of functions one more time all functions should be green:

But this time we could test our second function. Go to dataform-run-topic pubsub topic in the Messages tab and click Publish Message button:
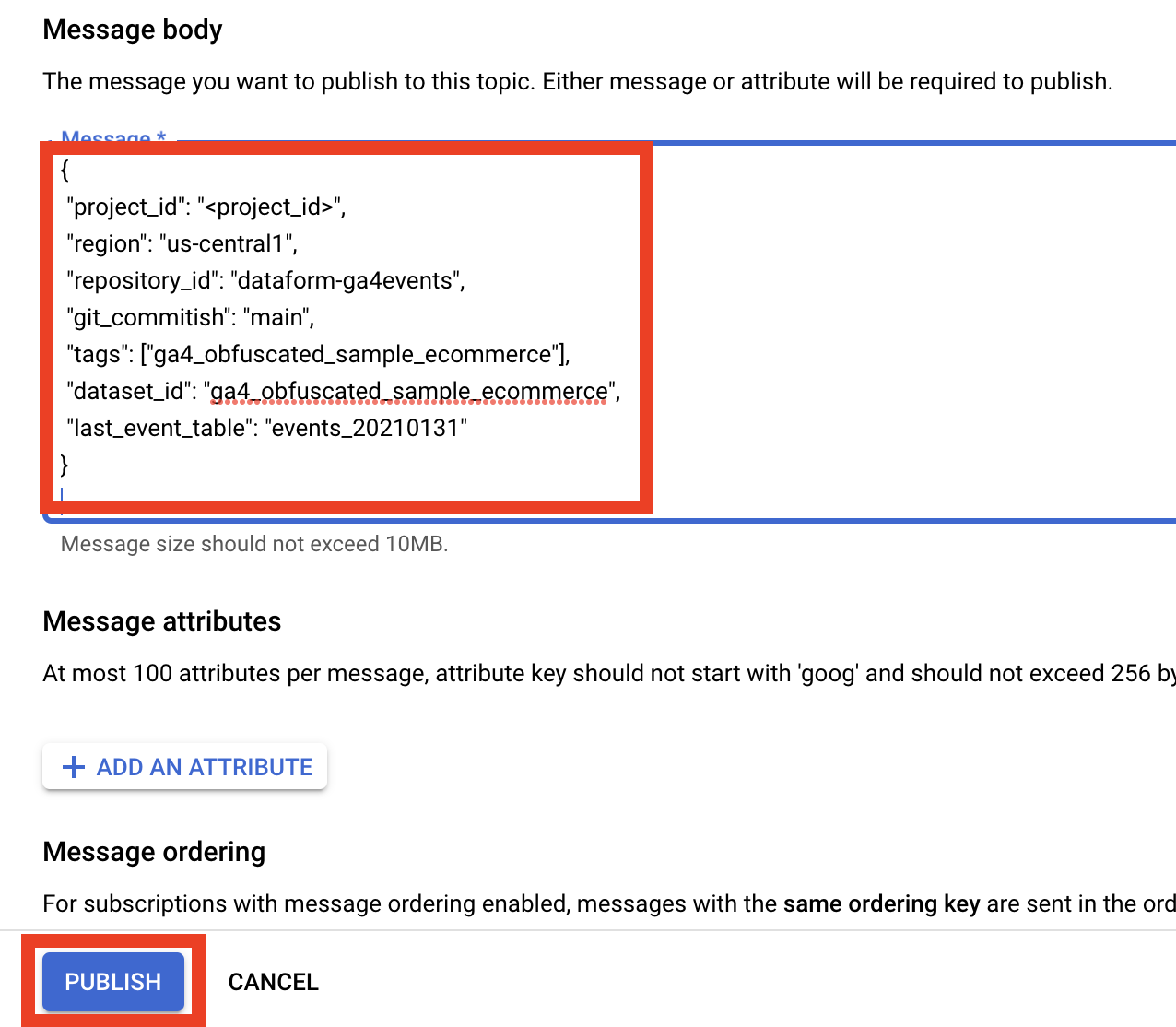
Put this object in the Message body (don’t forget to change <project_id> to your project):
{
"project_id": "<project_id>",
"region": "us-central1",
"repository_id": "dataform-ga4events",
"git_commitish": "main",
"tags": ["ga4_obfuscated_sample_ecommerce"],
"dataset_id": "ga4_obfuscated_sample_ecommerce",
"last_event_table": "events_20210131"
}
And let’s check the result, open the ga4-table-updated-dataform-run-func log tab
And the last log record should be something like this:
Function execution took 21865 ms, finished with status: ‘ok’

Then go to the Dataform workflow execution logs:
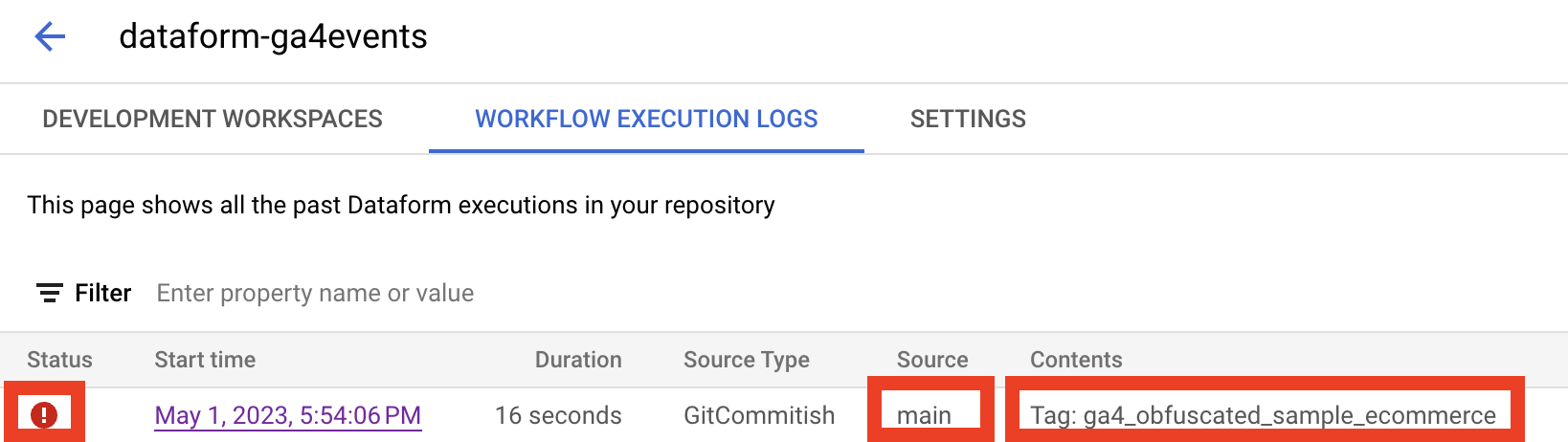
Here we can see the last execution from the source main with the tags ga4_obfuscated_sample_ecommerce but with an error status. If we click on this row we could find the reason:
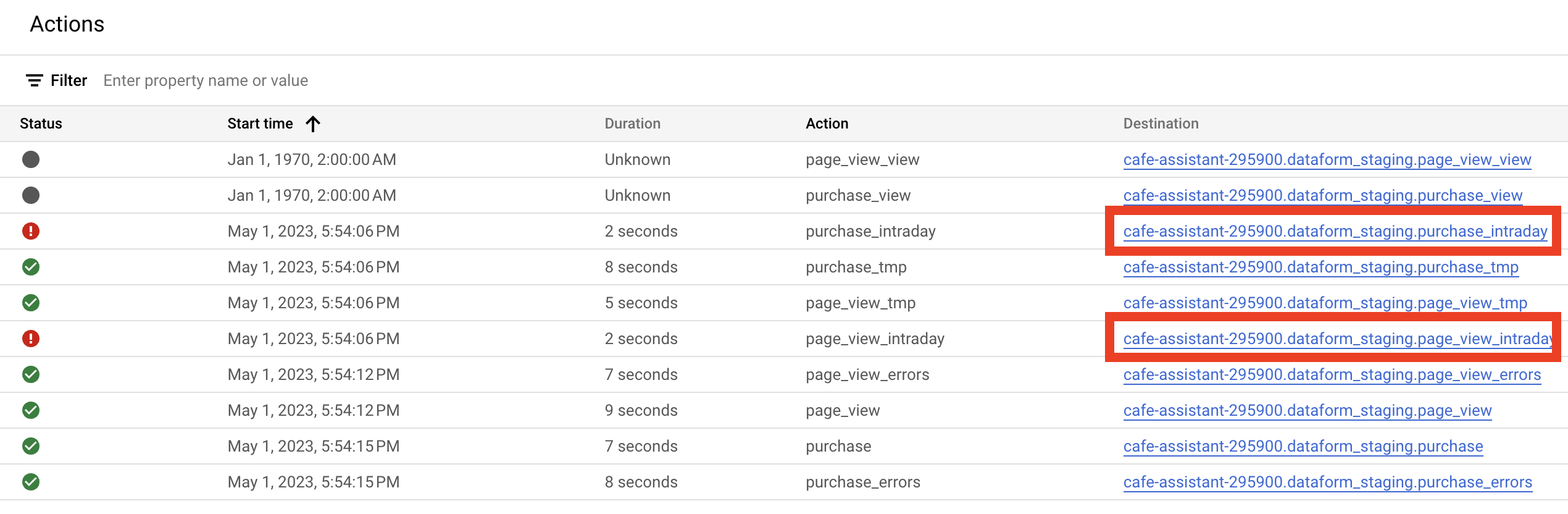
Our intraday models returned errors because Google doesn’t provide intraday datasets. But if you test on actual data all the actions should be green.
Hourly run
The last exercise in this post, let’s run an intraday update every hour. We will create a scheduler job to send to pubsub dataform-run-topic messages like this:
{
"project_id": "<project_id>",
"region": "us-central1",
"repository_id": "dataform-ga4events",
"git_commitish": "main",
"tags": ["ga4_hourly"]
}As you see we don’t specify dataset_id and table_name, as we want to execute all GA4 models with ga4_hourly tag.
First define the message
export message_body="{\"project_id\":\"${project_id}\",
\"region\":\"${region}\",\"repository_id\": \"${repository_id}\",
\"git_commitish\": \"${git_commitish}\",\"tags\":[\"ga4_hourly\"]}"We reuse existing variables and change the tags to ga4_hourly.
And next, create the job using gcloud scheduler jobs create pubsub command:
gcloud scheduler jobs create pubsub ga4-hourly --location ${region} \
--schedule "0 * * * *" --topic ${dataform_run_topic} --message-body ${message_body}Here important parameters are:
topic- we send event to dataform-run-topic, as you remember this message will run ga4-table-updated-dataform-run-func functionschedule- it’s a cron job schedule. And the easiest way to create cron rules is https://crontab.guru/every-1-hour
If it’s your first scheduler job in the project you will get this warning
API [cloudscheduler.googleapis.com] not enabled on project []. Would you like to enable and retry (this will take a few minutes)? (y/N)? Type ‘Y’, and in a few moments the job will be created
Let’s check the job. Go to the cloud scheduler page you should see something like this:

And for testing click the three dots in the job’s row, and in the dropdown menu click on Force run command.
As usual, you could check cloud functions logs and Dataform Workflow Execution Logs:
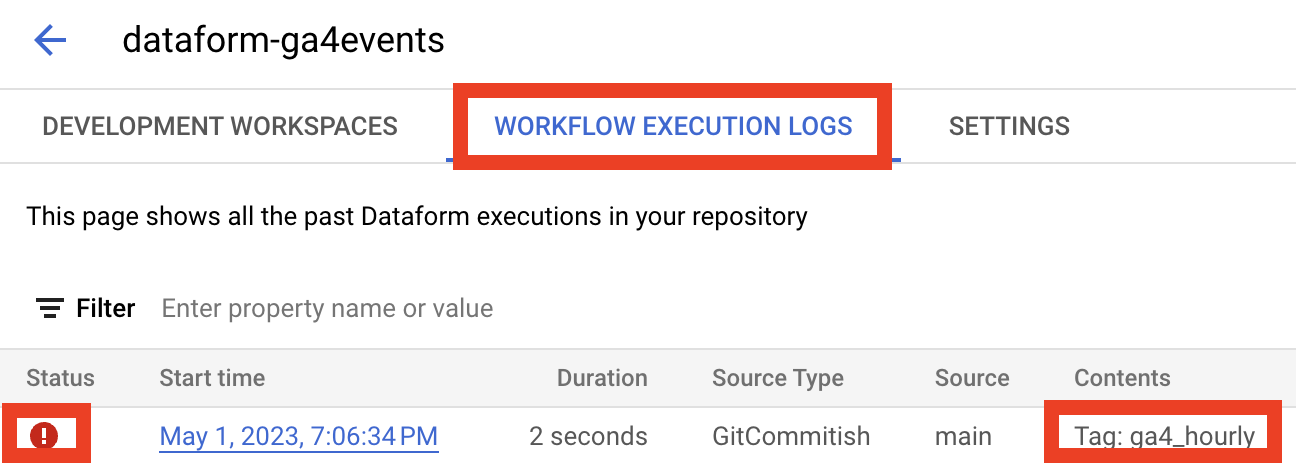
You should see execution with ga4_hourly tags but again in error status, as we don’t have an intraday GA4 dataset.
Remember to pause or delete the scheduler job after all your tests.
Final thoughts
Thanks for reading, in this post we used a few core Google Cloud services and played a bit with gcloud CLI. And now we are ready to run our GA4 pipelines as soon as somebody decides to buy one more Google t-shirt.

The following post should be about monitoring, Slack and Teams notifications.
Please message me on LinkedIn if you have any questions or comments.
PS A few useful links:
- Simo’s post How Do I Trigger A Scheduled Query When The GA4 Daily Export Happens?
- Taneli’s post how to run Dataform using Cloud Workflow – Run Dataform queries immediately after the GA4 BigQuery export happens
- Dataform package dataform-ga4-sessions to create session table based on GA4 BigQuery export data